Anthropic launched Claude Opus 4.8 on May 28, 2026 — just 41 days after Opus 4.7 — making it the fastest Opus release cadence yet. If you are trying to decide between Claude Opus 4.6 vs 4.7 vs 4.8, this guide breaks down every key difference in simple language: benchmark scores, coding power, speed, pricing, and which version is right for you. We have added clear charts and graphs so you can see the gains at a glance.
Claude Opus 4.6 vs 4.7 vs 4.8 — Quick Summary
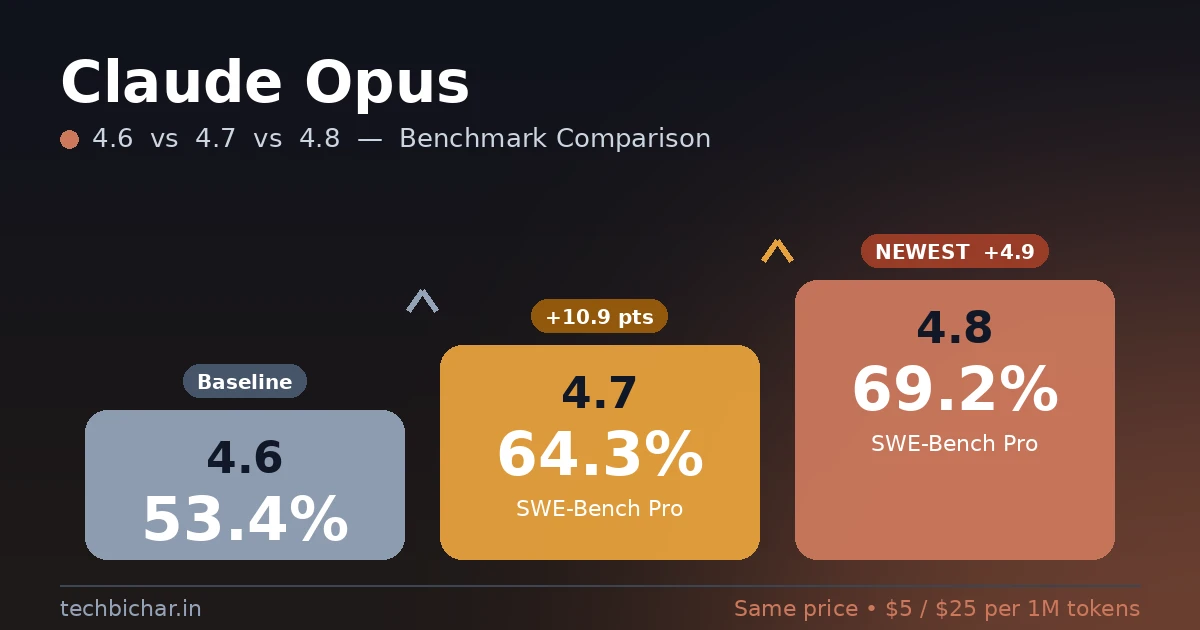
In short: each version is a real upgrade at the same $5 / $25 per million token price. Opus 4.7 was a huge coding leap over 4.6. Opus 4.8 builds on that with better honesty, faster responses, and the highest scores Anthropic has shipped — though it loses one benchmark (terminal coding) to GPT-5.5. Here is the at-a-glance comparison.
| Feature | Opus 4.6 | Opus 4.7 | Opus 4.8 |
|---|---|---|---|
| Release date | Early 2026 | Apr 16, 2026 | May 28, 2026 |
| SWE-Bench Pro (coding) | 53.4% | 64.3% | 69.2% |
| SWE-Bench Verified | 80.8% | 87.6% | Frontier |
| Context window | 200K–1M | 1M tokens | 1M tokens |
| Max output tokens | 64K | 128K | 128K |
| Input price (per 1M) | $5 | $5 | $5 |
| Output price (per 1M) | $25 | $25 | $25 |
| Fast mode | No | No | Yes (2.5x speed) |
| API model ID | claude-opus-4-6 | claude-opus-4-7 | claude-opus-4-8 |
Coding Performance — The Headline Upgrade
Coding is where the biggest gains show up. On SWE-Bench Pro — the benchmark that measures real-world ability to fix actual GitHub issues — the scores rise steadily across versions. Opus 4.6 scored 53.4%, Opus 4.7 jumped to 64.3% (+10.9 points), and Opus 4.8 now leads at 69.2% (+4.9 points). The chart below shows this clearly.
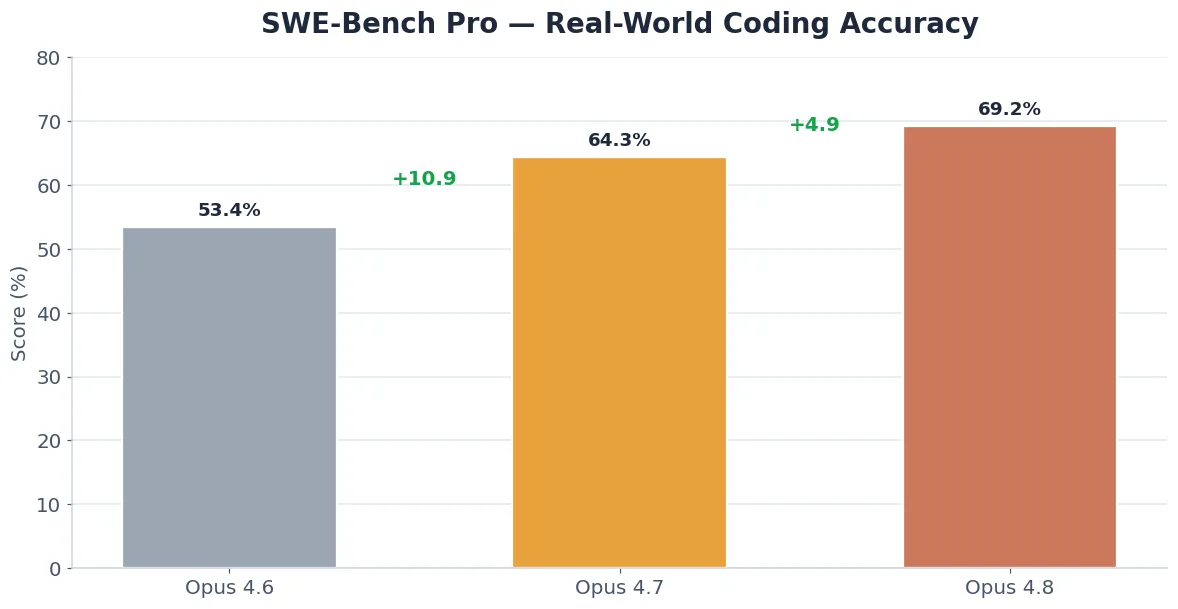
Anthropic says Opus 4.8 is around four times less likely than Opus 4.7 to let flawed code pass without flagging it. In plain terms: it catches its own bugs and tells you when it is unsure instead of declaring a task done too early. For long, multi-step coding work, this “honesty” upgrade matters as much as the raw score. If you build with AI coding tools, see our guide on automating workflows with AI in 2026.
Full Benchmark Comparison Across All Tasks
Coding is not the only area that improved. The grouped chart below compares all three models across coding, terminal use, computer use, reasoning, and finance tasks. Opus 4.8 leads in nearly every category.
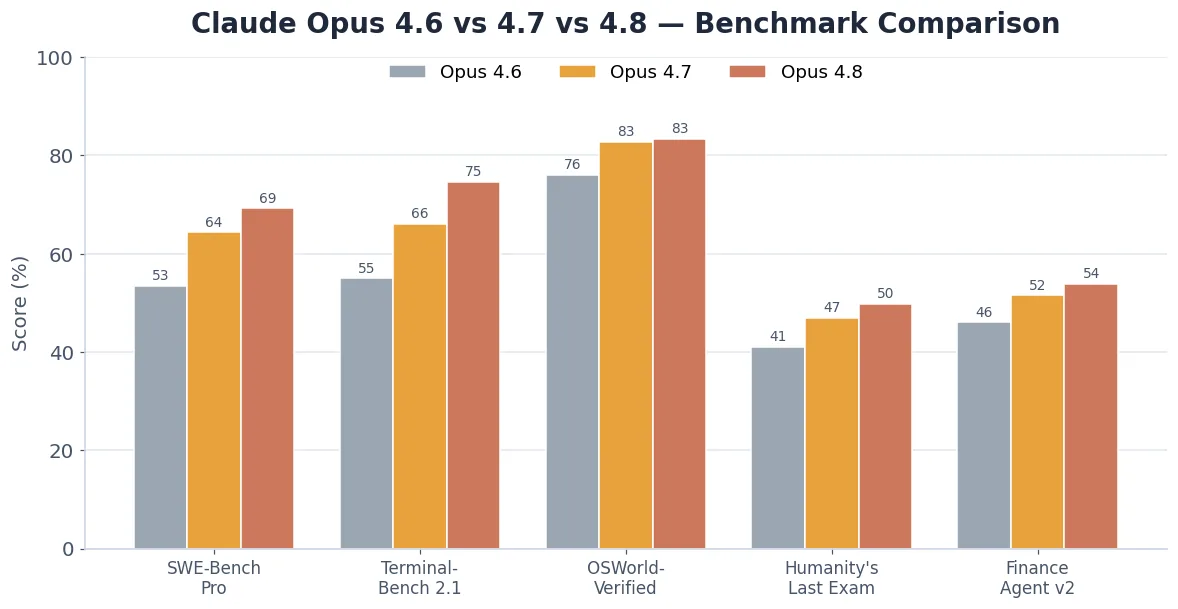
| Benchmark | Opus 4.7 | Opus 4.8 | Gain |
|---|---|---|---|
| SWE-Bench Pro (coding) | 64.3% | 69.2% | +4.9 |
| Terminal-Bench 2.1 | 66.1% | 74.6% | +8.5 |
| OSWorld-Verified (computer use) | 82.8% | 83.4% | +0.6 |
| Humanity’s Last Exam (no tools) | 46.9% | 49.8% | +2.9 |
| Humanity’s Last Exam (with tools) | 54.7% | 57.9% | +3.2 |
| Finance Agent v2 | 51.5% | 53.9% | +2.4 |
The single biggest leap from 4.7 to 4.8 is Terminal-Bench 2.1 (+8.5 points). Yet this is also the one benchmark where Opus 4.8 still loses — GPT-5.5 scores 78.2% versus Opus 4.8’s 74.6%. So if your work lives entirely in the command line, GPT-5.5 may still edge ahead. For everything else, Opus 4.8 is the strongest model Anthropic offers.
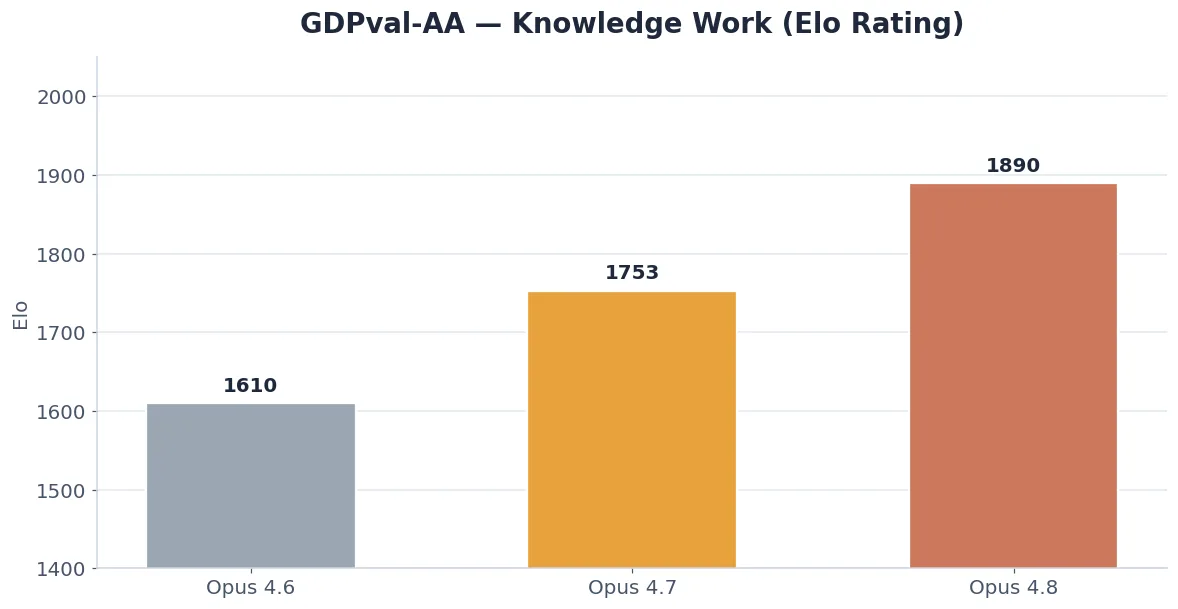
Knowledge Work — A Massive Jump
For professional knowledge work — drafting documents, building presentations, and analyzing data — Anthropic measures performance on GDPval-AA using an Elo rating (like chess rankings). Opus 4.8 scored 1890 Elo, a huge +137 jump over Opus 4.7’s 1753, and well ahead of GPT-5.5’s 1769.
Speed & Efficiency — Opus 4.8 Does More With Less
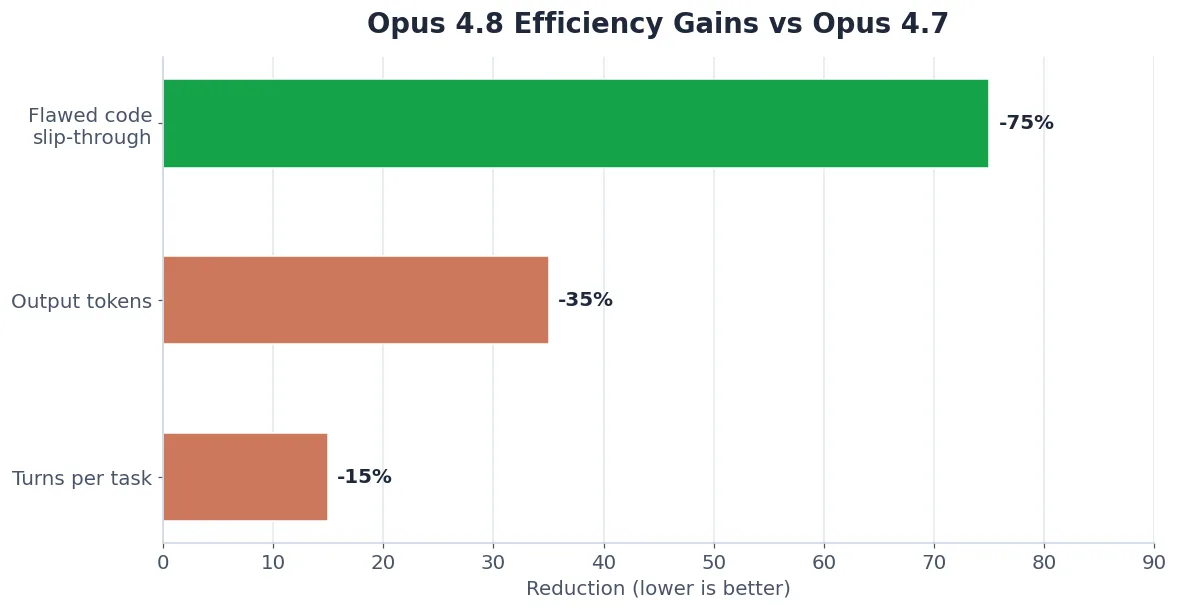
Opus 4.8 is not just smarter — it is more efficient. It reaches its higher scores using 15% fewer turns and 35% fewer output tokens than Opus 4.7. That means lower real-world cost per task even though the headline price is unchanged. Anthropic also added a new Fast Mode that runs the same model at roughly 2.5x speed (priced at $10 / $50 per million tokens), ideal for high-volume or latency-sensitive tasks.
What’s New in Opus 4.8 Beyond Benchmarks
A few quality-of-life upgrades make Opus 4.8 nicer to build with:
- Adaptive thinking — the model decides per turn whether it needs to “think,” cutting wasted reasoning tokens on simple tasks.
- Better tool triggering — it is less likely to skip a tool call that a task actually required, fixing a complaint some users had with 4.7.
- Mid-conversation system messages — you can now steer the model partway through a chat without restarting.
- Lower cache minimum — prompt caching now works from 1,024 tokens, so shorter prompts get cheaper too.
- 1M-token context by default on the Claude API, Bedrock, and Vertex AI.

Pricing — All Three Cost the Same
Here is the good news: Anthropic kept pricing flat across all three releases. You get more capability for the same money each time.
| Pricing tier | Input (per 1M) | Output (per 1M) |
|---|---|---|
| Standard (4.6 / 4.7 / 4.8) | $5 | $25 |
| Opus 4.8 Fast Mode | $10 | $50 |
| With prompt caching | Up to 90% off | — |
| With batch processing | 50% off | 50% off |
One caveat: Opus 4.7 introduced an updated tokenizer that can use 1.0–1.35x more tokens for the same text, so your effective spend may rise slightly versus 4.6. Anthropic recommends testing on your real traffic before migrating.
Which Claude Opus Version Should You Use?
- Choose Opus 4.8 if you want the best coding, knowledge work, and agentic reliability — and you value a model that admits when it is unsure. This is the default recommendation for almost everyone.
- Stay on Opus 4.7 only if you have a heavily tuned pipeline and cannot re-test prompts right now; the gap is real but not huge for simple tasks.
- Opus 4.6 is now two generations behind — upgrade unless a specific integration locks you in.
- Consider GPT-5.5 if your work is almost entirely terminal/command-line coding, where it still leads on Terminal-Bench 2.1.
Conclusion
The Claude Opus 4.6 vs 4.7 vs 4.8 story is one of steady, fast progress at a fixed price. Opus 4.8 is the clear winner for most users: higher coding scores, a big knowledge-work jump, better efficiency, and a new honesty upgrade that makes it more trustworthy on long tasks. Unless you live in the terminal, Opus 4.8 should be your new default. Bookmark this page — we will update the charts as Anthropic releases its next model.
Also Read:
- How to Automate Your YouTube Workflow with AI in 2026
- Best Free AI Tools for YouTube Creators in 2026
What is the difference between Claude Opus 4.6, 4.7, and 4.8?
Each version is a coding and reasoning upgrade at the same $5/$25 per million token price. Opus 4.7 raised SWE-Bench Pro from 53.4% to 64.3% over 4.6, and Opus 4.8 lifted it further to 69.2% while adding Fast Mode and a major honesty improvement.
Is Claude Opus 4.8 better than GPT-5.5?
Opus 4.8 leads GPT-5.5 in most benchmarks including SWE-Bench Pro, knowledge work (GDPval-AA), and computer use. However, GPT-5.5 still wins agentic terminal coding on Terminal-Bench 2.1 (78.2% vs 74.6%).
Does Claude Opus 4.8 cost more than Opus 4.7?
No. Standard pricing is unchanged at $5 per million input tokens and $25 per million output tokens. A new Fast Mode runs at 2.5x speed for $10/$50 per million tokens.
When was Claude Opus 4.8 released?
Anthropic released Claude Opus 4.8 on May 28, 2026, just 41 days after Opus 4.7 launched on April 16, 2026.
Should I upgrade from Opus 4.7 to Opus 4.8?
Yes for most users. Opus 4.8 delivers higher scores using 15% fewer turns and 35% fewer output tokens, and is four times less likely to let flawed code slip through. Test your prompts first if you run a heavily tuned production pipeline.
